Monolithic repositories for microservice applications
When starting up a project with multiple components, you have a number of options:
- Entirely decoupled services, in separate repositories
- Mostly decoupled services, in a single repository
I'd like to discuss why we went with the latter, and what lead us to that path.
The problem: Discrete repositories
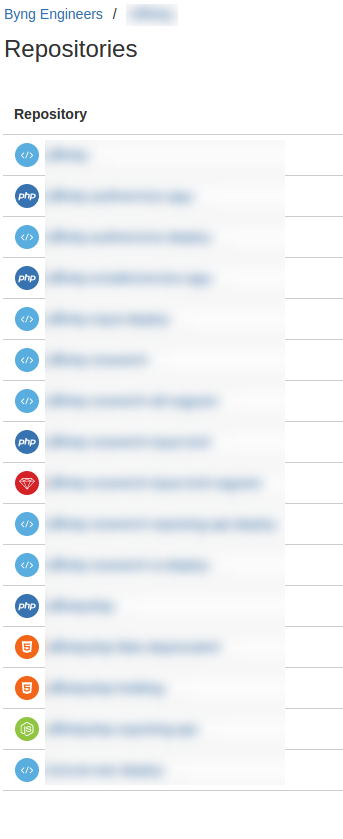
In the screenshot above, for one of our my company's live projects that benefits from a micro-services approach, there are eighteen repositories. Roughly half of them are 'deploy' repositories, only used by our CI platform to hold Ansible playbooks or similar.
Which leaves a lot of discrete repositories which must be cloned and set up by any new developer joining the project. As one of the components is an authentication service, practically everything else needs to know where to find that, leaving scripts like this being passed around between developers:
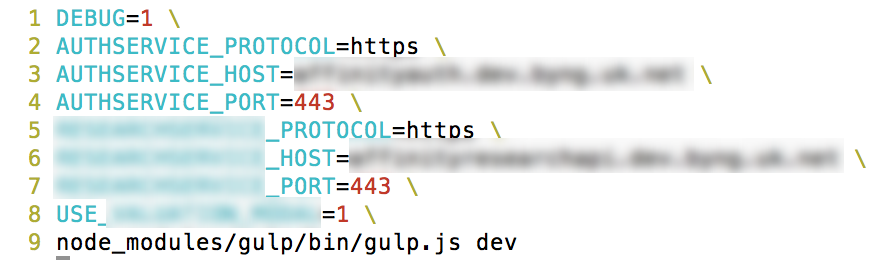
- And this isn't even one of the more complex ones!
One of our (exceedingly bright and capable) developers spent around a day trying to set this up properly. Multiply that out by a few more people joining a project and it starts to become a very expensive issue.
In addition, when a change is made in one component that is required for another, as a developer working on the project you need to keep all the clones in sync, not just the one or two that you happen to be working on, otherwise you end up with very hard to pin down errors.
Our current solution: Monolithic repository + Docker
By way of comparison with the scary image above, here is another of our projects running as a monolithic repository, with four discrete components:
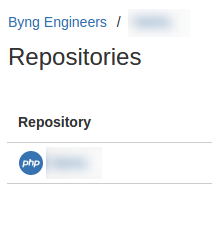
And within that repository is a README file, containing the instruction
Steps:
- Run
docker-compose up -d
And so a new developer can get started on the project in a matter of minutes. It'll take them more time to read about the project components than it will for their setup to come online.
This is perhaps a little unfair. The second project is stateless as it talks to external APIs, so there is no database to pull or image assets to sync. However that is easy enough to solve by writing a simple dump.sh file, as the script author will know where all the services are located and where it will find the database due to the docker-compose.yml file.
In fact, this is the approach we've taken with the first project. There is a repository in the project simply named the same as the project, which expects to be cloned into the same directory as all the other services.
Fringe benefits
So besides quicker setup, what else do you get?
Cross-service changes
At my current company, we code review every change. If a task requires a change in more than one component, this means multiple code-reviews. For example, adding a new permission to the authentication service that another service will use.
With a modular repository structure, this involves multiple pull-requests, and code-reviews possibly by different people. This can lead to the reviewer losing the context of the change and having to fall back on syntax and code-style issues.
Without a monolithic repository to handle all the component PRs in one place, a reviewer might easily miss a permission being named READ_FOOS on one end and READ_FOO on the other for example.
Encourages knowledge about the structure
With something as convoluted as the first image in this article, as a developer joining the project you would be forgiven for only setting up the parts you absolutely need in order to start work. When it is just as easy to set up the entire project as it is to set up a couple of parts of it, and the connections between the projects are easily expressed single README.md and docker-compose.yml files, it is much easier for a developer to learn how things are set up purely through curiosity.
Partially centralises logging
While a proper log analysis flow is ideal, for development it seems like overkill, right up until you need it.
With properly set up docker containers (a few judicious tail -f logs/*log & help pull in straggling log files missed by container developers) a developer can view all the output from the entire project with docker-compose logs -f while they're editing and debugging.
Challenges introduced
Sadly it isn't all roses and sunbeams.
Requires knowledge of docker
Docker does introduce a few things to be aware of. For instance, that you're probably not running the same version of node inside the container as out, so your npm install sass might break because it needs rebuilding inside the node container. Or for a simpler example, you'll need to know what port (if any) your database is exposed on so you can import a copy to get started.
Services need to be aware of eachother's startup times
When booting a docker-compose file, your services all start up at the same time. Ideally they should be able to handle waiting for their dependencies to come online, as they'll need to handle it gracefully in production when scaling up/down, but it can't be avoided with a magic dance like 'always run the Foo deploy before the Bar deploy'.
Migration time
If you're starting with a modular-repository project, there will be some effort associated with migrating it to a monolithic repository. You'll need to stop the whole machine, change everything, rebuild your CI process and start it up again. It is messy, but can't be avoided.
Think of the time as being spent avoiding future slow onboardings, or developers leaving in frustration for pastures-new.
What happened after we tried a monolithic repository
Even though the monolithic-repository project above is much younger than the first, we're already seeing great velocity on that project vs the original, modular-repo project. Had we seen the wired article earlier, maybe we would have saved ourselves from the conventional wisdom of separate-service-separate-repository.
We haven't (and don't intend) to go to the extreme of moving all projects into a single repository, as although the quick-setup benefits carry over, it also enforces quite a bit of unnecessary rigidity in project structure, and as some commenters have pointed out requires a lot of disk space to maintain legacy projects, and a lot of noise in git log on unrelated projects. If we were a product focused company we may consider it, but the issues outweigh the benefits for us as an agency company.
So by now you'll understand our decision to migrate to a per-project monolithic repository over a group of modular repositories per project. I hope it was helpful, and might be useful when you're starting your next project!